Da PDF a DOCX con Python: script batch e soluzioni affidabili che funzionano davvero

Sommario
Scopri come convertire PDF in DOCX con Python: dalle librerie più usate (pdf2docx, PyMuPDF) agli strumenti desktop professionali. Vedrai esempi pratici per conversioni in batch, OCR per PDF scansionati e automazioni che monitorano le cartelle, per un flusso di lavoro documentale più stabile ed efficiente.


| Tipo di problema | Causa tipica | Verifica preliminare / Diagnosi |
|---|---|---|
PDF scansionati | Nessun testo selezionabile | Apri il PDF e prova a evidenziare il testo; se non si evidenzia nulla, è necessario l'OCR |
Tabelle/layout complessi | pdf2docx non ha un motore di layout | Converti prima una pagina e controlla se ci sono colonne spostate |
Font incorporati / testo distorto | Sottoinsiemi di font o codifica non standard | Esamina il DOCX alla ricerca di □ o simboli casuali |
Crash con batch grandi | Conflitti di memoria o dipendenze | Testa con 5-10 file; tieni d'occhio l'uso della RAM |

| Approccio | Ideale per | Limitazione principale |
|---|---|---|
pdf2docx | Conversioni rapide di PDF digitali | Debole con layout complessi; nessun OCR |
PyMuPDF + python-docx | Controllo completo e logica di estrazione personalizzata | Richiede molta programmazione per la ricostruzione del layout |
pdfplumber | PDF incentrati su tabelle | Nessun output DOCX; solo estrazione testo |
Pandoc | Pipeline scriptabili; flussi di lavoro multi-formato | La qualità PDF→DOCX dipende dai lettori LaTeX/PDF |
LibreOffice CLI | Automazione batch; conversione headless | La fedeltà del layout varia; nessun OCR |
| Funzionalità | Supporto |
|---|---|
PDF→DOCX diretto | Sì |
OCR | No |
Font incorporati | Parziale |
Layout complessi | Moderato |
Automazione | Sì |
Moduli XFA | No |
| Funzionalità | Supporto |
|---|---|
PDF→DOCX diretto | No (codifica manuale) |
OCR | No (OCR esterno necessario) |
Font incorporati | Sola lettura |
Layout complessi | Alto controllo, manuale |
Automazione | Eccellente |
Moduli XFA | No |
| Funzionalità | Supporto |
|---|---|
PDF→DOCX diretto | No |
OCR | No |
Font incorporati | No |
Layout complessi | Buono per le tabelle |
Automazione | Sì |
Moduli XFA | No |
| Funzionalità | Supporto |
|---|---|
PDF→DOCX diretto | Sì (via LaTeX) |
OCR | No |
Font incorporati | No |
Layout complessi | Limitato |
Automazione | Eccellente |
Moduli XFA | No |
| Funzionalità | Supporto |
|---|---|
PDF→DOCX diretto | Sì |
OCR | No |
Font incorporati | Parziale |
Layout complessi | Moderato |
Automazione | Eccellente |
Moduli XFA | No |

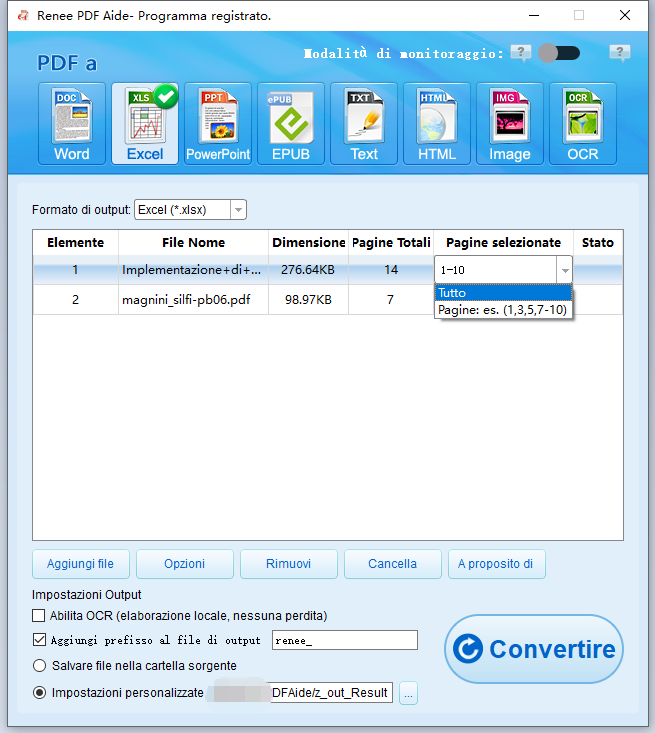
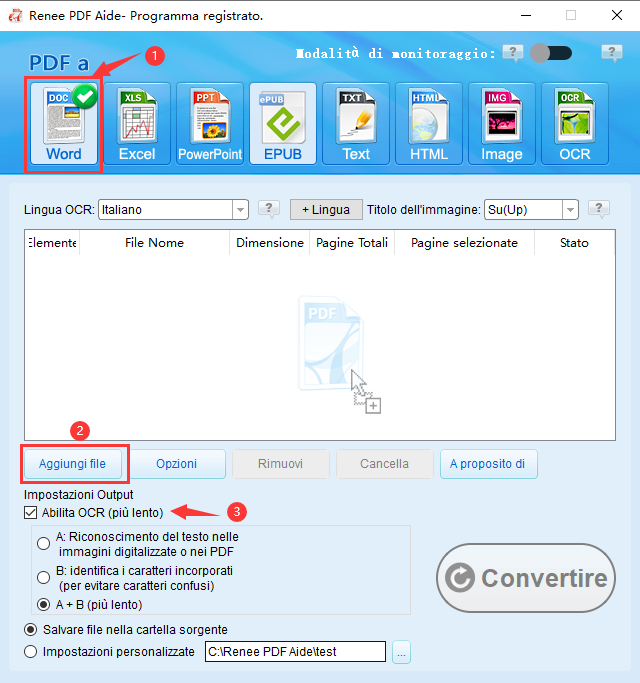
Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Varie funzioni di modifica Crittografia/decrittografia/divisione/unione/filigrana ecc.
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
La modifica/conversione è veloce Modifica/converti rapidamente più file contemporaneamente.
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Vantaggi principali:

Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Varie funzioni di modifica Crittografia/decrittografia/divisione/unione/filigrana ecc.
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
La modifica/conversione è veloce Modifica/converti rapidamente più file contemporaneamente.
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Passaggi
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
Limitazioni
- Controllo completo del codice e personalizzazione
- Gratuito per PDF nativi semplici
- Facile integrazione nelle pipeline Python esistenti
Cons:
- Nessun OCR integrato per documenti scansionati
- Tabelle complesse e immagini spesso si disallineano
- Richiede strumenti esterni per l'esecuzione programmata
- Necessario un debug approfondito per diversi layout PDF
| Caso d'uso | Strumento consigliato |
|---|---|
Test rapido su 1-2 PDF semplici | Script Python pdf2docx |
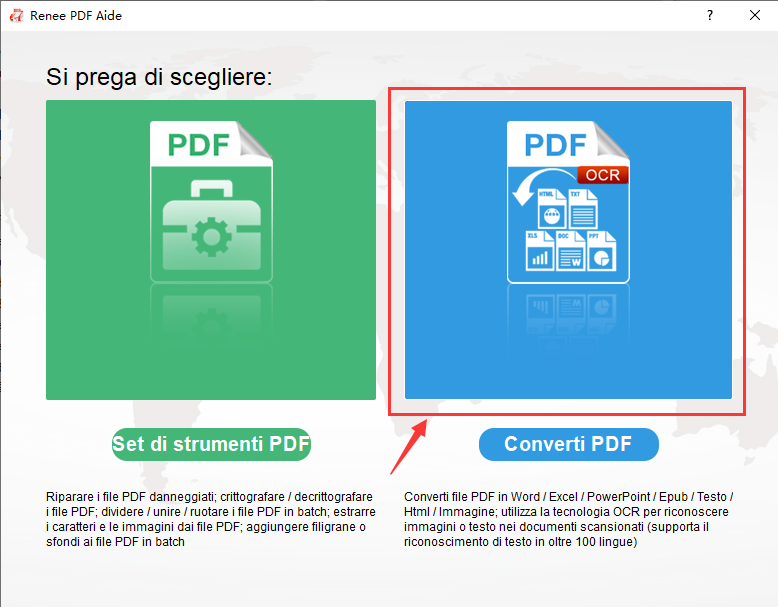
PDF scansionati o layout complessi | Renee PDF Aide con OCR |
Conversione batch (oltre 50 file) | Renee PDF Aide (modalità batch + monitoraggio) |
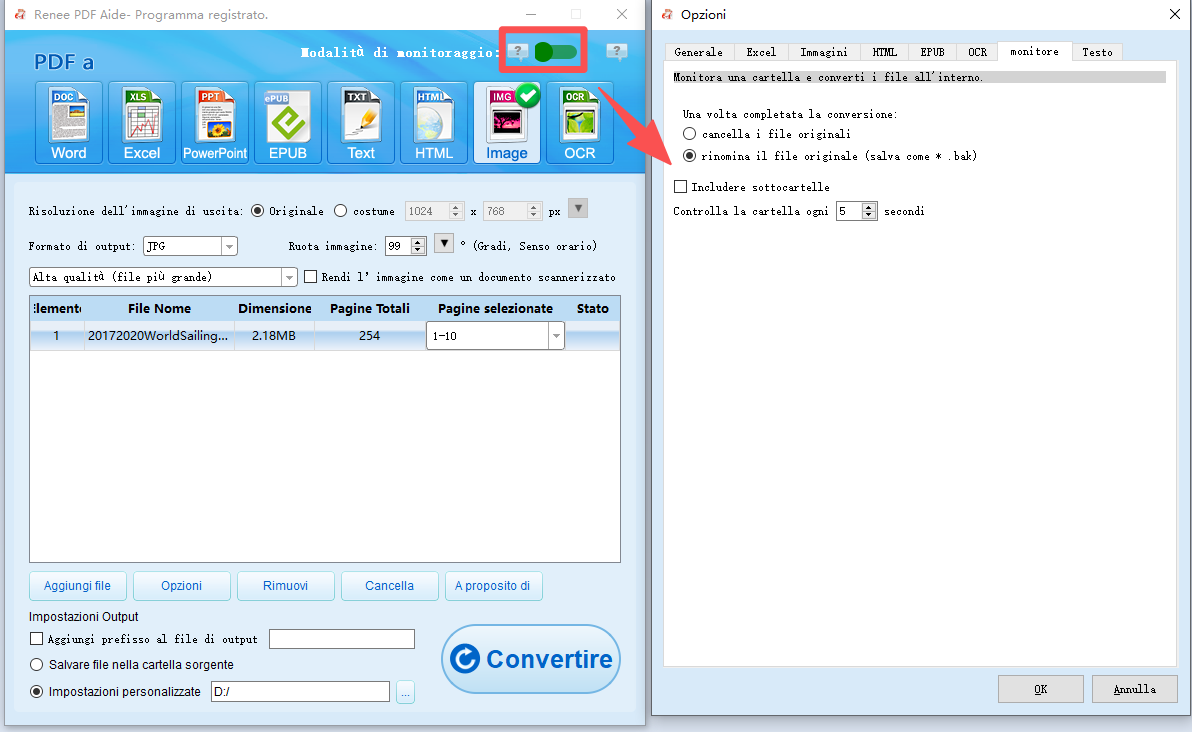
Conversioni notturne programmate | Modalità monitoraggio Renee PDF Aide |
Controllo completo del codice + PDF semplici | Script personalizzato PyMuPDF + watchdog |
Renee PDF Aide può gestire PDF scansionati che gli script Python non riescono a leggere?
Perché pdf2docx perde la formattazione delle tabelle o l'allineamento delle colonne?
Qual è la dimensione massima del batch o il limite di pagine in Renee PDF Aide?
Posso convertire PDF protetti da password in DOCX con Python o Renee PDF Aide?
Renee PDF Aide funziona con i moduli XFA (PDF bancari/governativi)?

Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Varie funzioni di modifica Crittografia/decrittografia/divisione/unione/filigrana ecc.
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
La modifica/conversione è veloce Modifica/converti rapidamente più file contemporaneamente.
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Articoli correlativi :
Come Estrarre Tabelle da PDF: Soluzioni Gratuite e AI per Risparmiare Tempo

28-10-2025
Giorgio : Scopri come estrarre facilmente tabelle da PDF nel 2025 con strumenti gratuiti e soluzioni AI avanzate, perfette per...
Trucchi Rapidi per Estrarre Testo dai PDF con Facilità

03-10-2025
Lorena : Vuoi estrarre testo da un PDF in modo semplice e veloce? In questa guida scoprirai come farlo gratis,...


Commenti degli utenti
Lascia un commento