Trucchi Rapidi per Estrarre Testo dai PDF con Facilità

Sommario
Vuoi estrarre testo da un PDF in modo semplice e veloce? In questa guida scoprirai come farlo gratis, grazie a strumenti pratici e alla tecnologia OCR. Che tu debba copiare poche righe o interi documenti, troverai la soluzione giusta per te.

Indice dei contenuti


Passaggi per copiare e incollare il testo pagina per pagina


La copia del testo dal PDF produce caratteri illeggibili
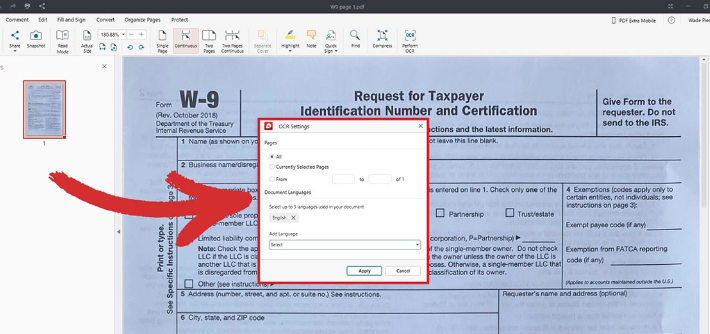
File PDF scannerizzati

Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Varie funzioni di modifica Crittografia/decrittografia/divisione/unione/filigrana ecc.
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
La modifica/conversione è veloce Modifica/converti rapidamente più file contemporaneamente.
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Come usare l'IA per l'estrazione del testo
Extract all text from this image and do not summarize the text.
Extract all text from this pdf file.

In molti casi, gli utenti devono catturare manualmente screenshot pagina per pagina, un’operazione che richiede tempo ed è soggetta a errori. Per carichi di lavoro più grandi o per uso professionale, un software desktop dedicato rimane la scelta più affidabile ed efficiente.
📊 Gestione PDF: Piani gratuiti e a pagamento (Aggiornamento 2025)
| Piattaforma | Versione Gratuita | Versione a Pagamento / Premium | Supporto Conversione PDF | Formati di Output | Miglioramenti AI-OCR 2025 |
|---|---|---|---|---|---|
Microsoft Copilot | Carica PDF fino a 50 pagine; dividi file più grandi. Si integra con Edge per un OCR rapido. | Microsoft 365: Pagine illimitate, estrazione di tabelle potenziata dall'IA. | ❌ Nessuna conversione diretta, ma esporta in JSON tramite API. | Testo semplice, JSON | Servizi Cognitivi v3.1: 98% di precisione per documenti scannerizzati. |
ChatGPT (OpenAI) | Nessun caricamento diretto; incolla testo o screenshot. | Plus/Team: Carica fino a 300 pagine; OCR automatico per le immagini. | ❌ Riassume soltanto; usa plugin per l'esportazione. | Testo semplice, elenchi puntati | Integrazione LlamaParse: Gestisce PDF multilingue (es. inglese+hindi). |
Grok (xAI) | Carica circa 50 pagine; ricerca semantica del testo. | Premium: circa 200 pagine, elaborazione batch. | ❌ Solo testo semplice. | Testo semplice | OCR migliorato per scansioni di bassa qualità; focalizzato sulla privacy. |
Cos'è Renee PDF Aide?
Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Varie funzioni di modifica Crittografia/decrittografia/divisione/unione/filigrana ecc.
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
La modifica/conversione è veloce Modifica/converti rapidamente più file contemporaneamente.
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Converti in formati modificabili Word/Excel/PowerPoint/Testo/Immagine/HTML/EPUB
Supporto OCR estrai testo da PDF scansionati, immagini e font incorporati
Compatibilità Windows 11/10/8/8.1/Vista/7/XP/2000
Estrarre Testo in Word

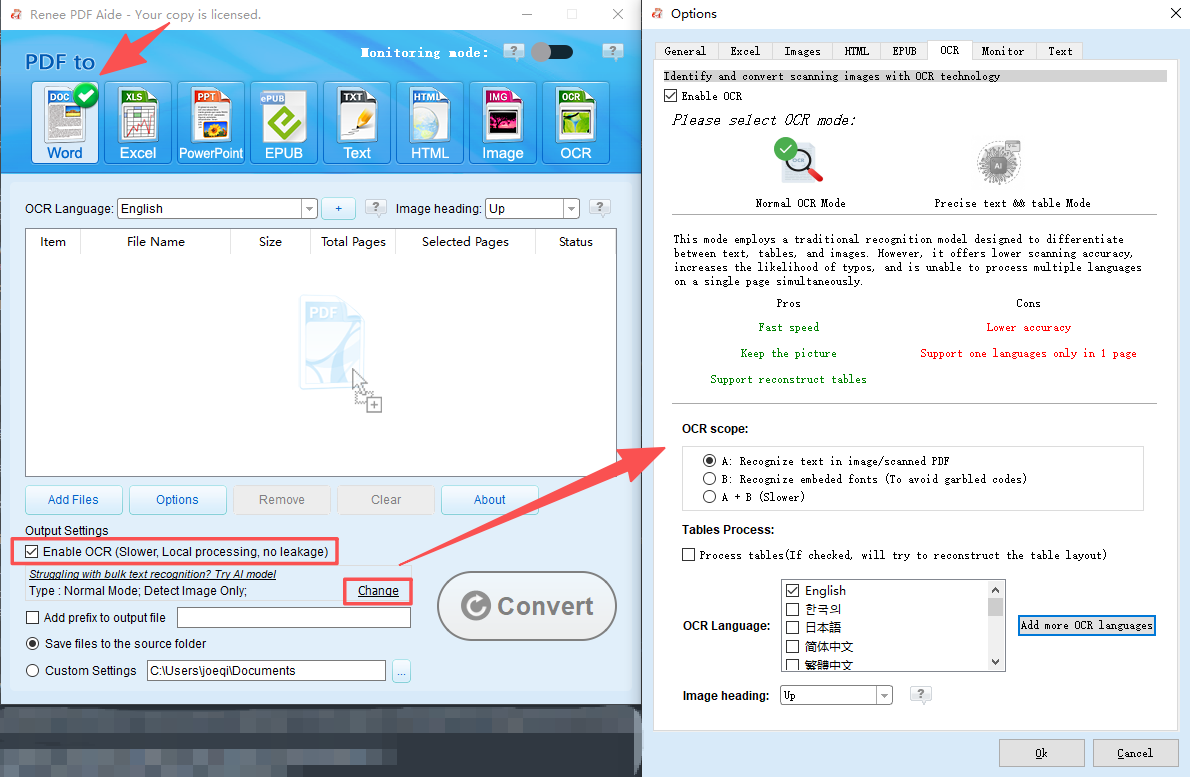
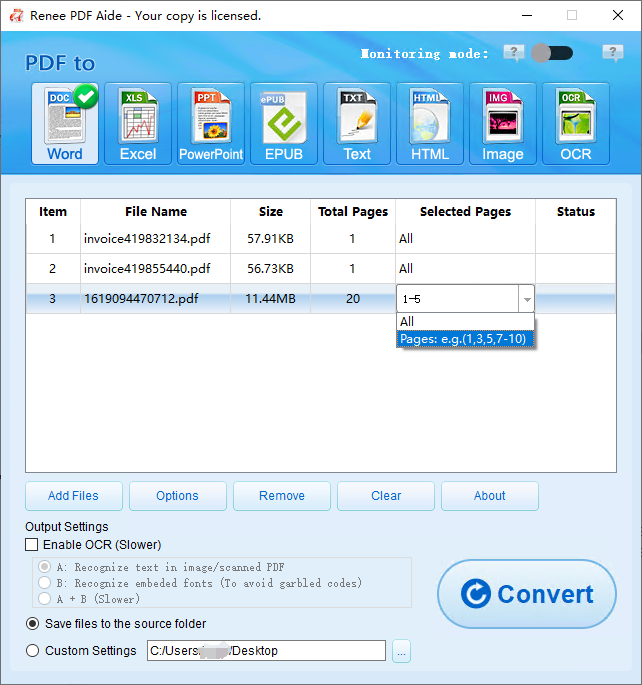

Estrarre Testo in Excel
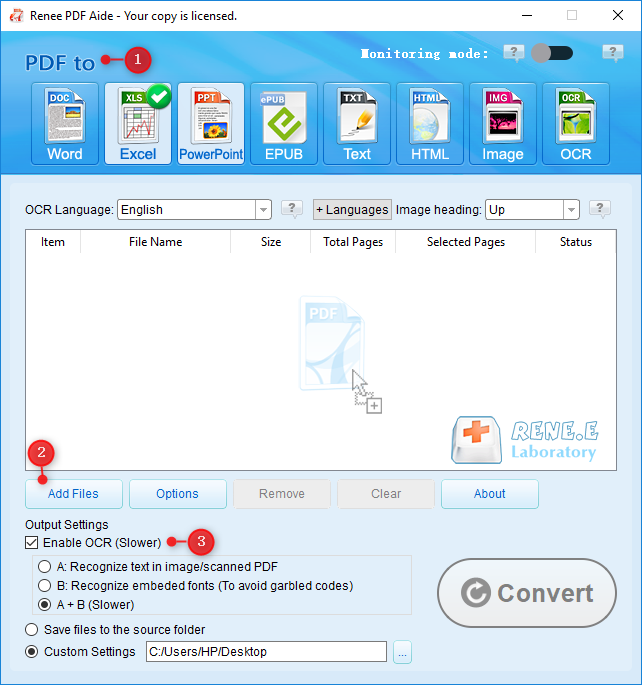
Estrarre Testo in PowerPoint
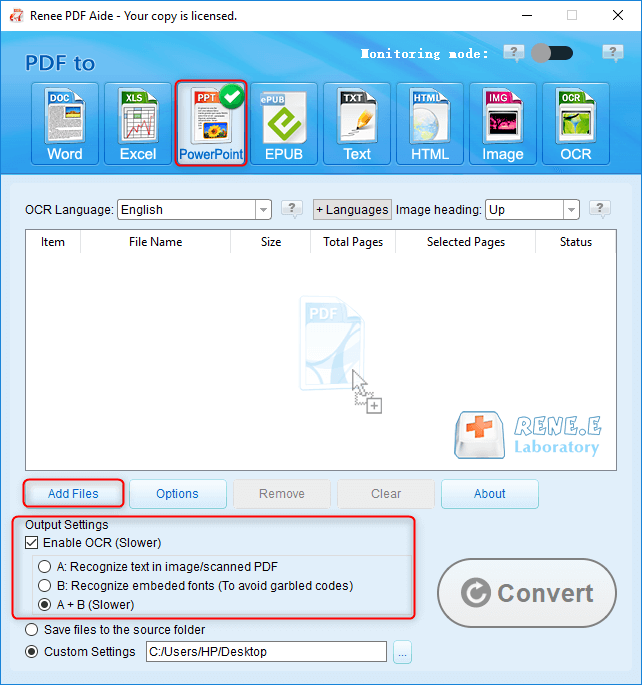
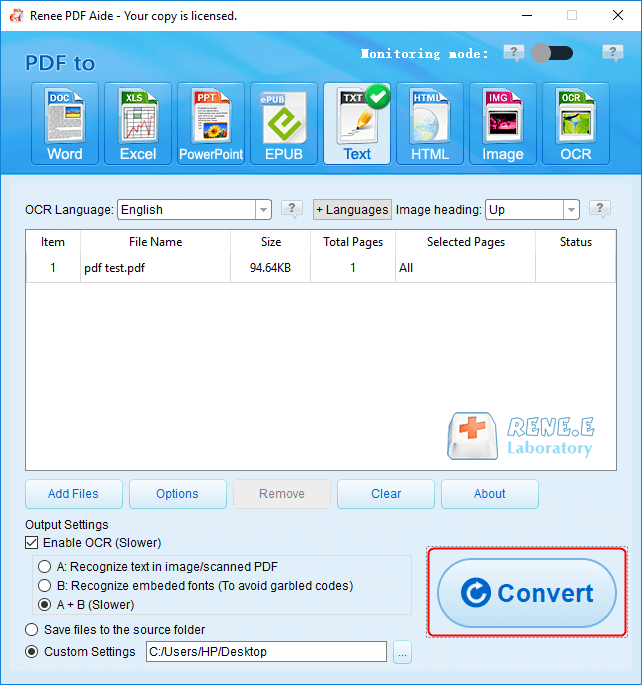
Estrarre Testo in TXT

| Strumento | Caratteristiche | Limitazioni |
|---|---|---|
PDF Candy | Conversione gratuita da PDF a TXT, OCR automatico per file scannerizzati, interfaccia user-friendly. Ideale per estrarre elenchi di prodotti dai cataloghi. | Limiti di dimensione del file (~100 MB), pubblicità nella versione gratuita, più lento durante le ore di punta, rischi per la privacy dovuti al caricamento su server. |
PDF2Go | Nessuna registrazione richiesta, supporta dispositivi mobili, conversione veloce in TXT con OCR. Ottimo per prendere appunti rapidi da PDF di riunioni. | Dimensioni file limitate, potenziale esposizione dei dati, perdita occasionale di formattazione, connessione internet richiesta. |
Esempio di script Python
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path, output_format="txt", lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = []
for page_num, page in enumerate(doc, start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- Pagina {page_num} ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
ocr_text = pytesseract.image_to_string(img, lang=lang)
text_output.append(f"--- Pagina {page_num} (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)[0]}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file, "w", encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("Formato di output non supportato. Usa 'txt' o 'docx'.")
return output_file
except Exception as e:
print(f"Errore durante l'elaborazione del PDF: {e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file, output_format="txt", lang="eng+hin")
if result:
print(f"Testo estratto in: {result}")✅ Pro: Gratuito, personalizzabile
❌ Contro: Richiede configurazione
hin+eng per un OCR accurato. Salva come TXT per testo semplice o Word per una modifica formattata.| Tipo di Utente | Metodo Migliore | Pro | Azione Successiva |
|---|---|---|---|
Principiante | Copia-incolla o Strumenti Online | Semplice, nessun costo o competenza richiesta. | Apri oggi il tuo PDF in Foxit Reader. |
Professionista | Renee PDF Aide | Conversioni veloci in Word/Excel, sicuro e offline. | Scarica la versione di prova dal sito ufficiale. |
Esperto di Tecnologia | Python con OCR | Automatizzato, scalabile per grandi quantità di dati. | Installa le dipendenze e testa il codice. |
Utente Mobile | Assistenti AI | Funziona ovunque con una connessione internet. | Prova ChatGPT Plus per i caricamenti. |
Cosa fare se il testo estratto è illeggibile o incompleto?
Gli strumenti online sono sicuri per i PDF sensibili?
Posso estrarre testo da PDF crittografati?
Come gestisco PDF di grandi dimensioni (ad es. 500+ pagine)?
Come posso estrarre testo da PDF multilingue?
hin+eng) per un’estrazione accurata da PDF bilingue.L'estrazione del testo mantiene la formattazione originale del PDF?
Articoli correlativi :
OCR AVX di Renee PDF Aide: Come Risolvere i Problemi di Compatibilità e Migliorare le Prestazioni

25-08-2025
Giorgio : Scopri come AVX rende l’OCR di Renee PDF Aide più rapido e preciso. Controlla se il tuo processore...
PDF in Excel: Come Trasformarli Facilmente con Excel
10-06-2025
Giorgio : Scopri come importare facilmente dati da PDF a Excel: ti mostriamo i metodi più rapidi con Excel e,...
Converti PDF in Google Fogli: Soluzione Facile e Veloce

10-06-2025
Sabrina : Scopri come convertire facilmente file PDF in fogli Google Excel. Ti mostriamo i passaggi migliori con Google Drive,...
PDF a Excel: Come Estrarre Testo Facilmente e Senza Errori

10-06-2025
Roberto : Scopri come estrarre facilmente testo da PDF a Excel con i migliori strumenti e tecniche. In questa guida...


Commenti degli utenti
Lascia un commento